An innovative approach to evidence generation from EHR provider notes using natural language processing and large language models

Written by: Janna Manjelievskaia, PhD, MPH; Elizabeth H. Marchlewicz, PhD, MPH; Theresa Sudaria, MS; Amanda Manfredo, PharmaD; and Jennifer Falk, DPM, MS
Introduction
Natural language processing (NLP) and large language models (LLMs) are increasingly being used in real-world evidence (RWE) generation to examine provider notes and offer deeper insights into decision making at the point of care. Veradigm’s data science and real-world evidence teams presented findings in cardiovascular research using NLP and LLM at the American College of Cardiology (ACC) Annual Meeting earlier this year.
Dataset overview
As one of the largest de-identified ambulatory electronic health record (EHR) datasets, Veradigm Network EHR Data contains over 152 million patients with clinical activity spanning more than 10 years. Veradigm Network EHR Data offers a unique perspective into the patient journey through a combination of structured data, natural language processing EHR-enhanced data, and unstructured clinical notes.
Structured EHR data, such as lab, imaging, and procedure results, are well suited for capturing clinical measures, questionnaires, and patient-reported outcomes. NLP-enhanced EHR data comb through provider notes using NLP to identify additional test results and patient responses, which are then converted into a structured format to increase sample size of structured data elements. Unstructured EHR data can support custom queries to mine free text of healthcare provider notes and unlock novel insights into provider rational and decision-making processes.
Importance of non-standard lipid markers in risk prediction: structured data
The analysis shared at the ACC meeting leveraged the use of NLP and LLMs to build upon Veradigm’s published research in apolipoprotein B and lipoprotein(a), which focused on screening rates, identifying discordance with standard lipid markers, and risk prediction. When examining screening rates among adults in the Veradigm Network EHR dataset, we found extremely low rates of apoB and lp(a) lab results from 2019-2024 (denominator varied by year, approximately 48-65 million adults). While there was a modest increase in the proportion of patients with an available lab result, overall rates were below 1% (Figure 1).
Figure 1. Proportion of adults in the Veradigm EHR with an available lab result, 2019-2024
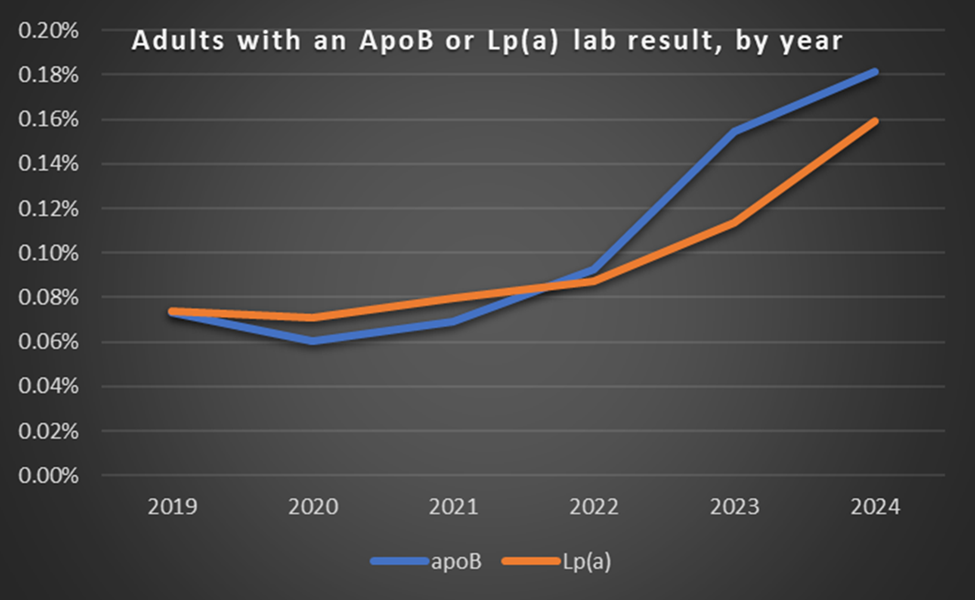
Denominator limited to adults with clinical activity in a given year: approximately 48-65 million adults per year.
In apoB specifically, we identified a substantial proportion (~20%) of adults with discordant apoB/LDL-C values. Those in the discordant high-risk group (high apoB, low LDL-C) had the highest risk of incident hypertension. These findings suggest that current lipid screening guidelines miss a substantial proportion of adults at risk of hypertension when relying on standard lipid panels.
In lp(a) specifically, we examined variation in lp(a) and acute myocardial infarction (AMI) association by number of standard modifiable risk factors (SMuRFs). Patients in the extreme high lp(a) cohort were more likely to have 3 or more SMuRFs and baseline risk factors compared to those in the low lp(a) cohorts. Patients with a higher number of baseline SMuRFs were more likely to have an AMI event and other risk factors in the follow-up period, underscoring a pressing public health need.
Despite the significant proportion of the US population that is either discordant in their apoB/LDL-C values or has elevated lp(a) levels, screening rates remain low. Using NLP and LLMs was an opportunity to examine provider rationale and decision-making around screening of these non-standard lipid markers.
Application of LLMs and NLP within Veradigm Network EHR Data
Veradigm’s data scientists enrich clinical data by applying natural language processing EHR techniques and machine learning to unstructured clinical notes. Here, we outline the NLP process to extract lp(a) and apoB mentions from clinical notes (Figure 2).
Figure 2. NLP process to extract Lp(a) and ApoB mentions from clinical notes
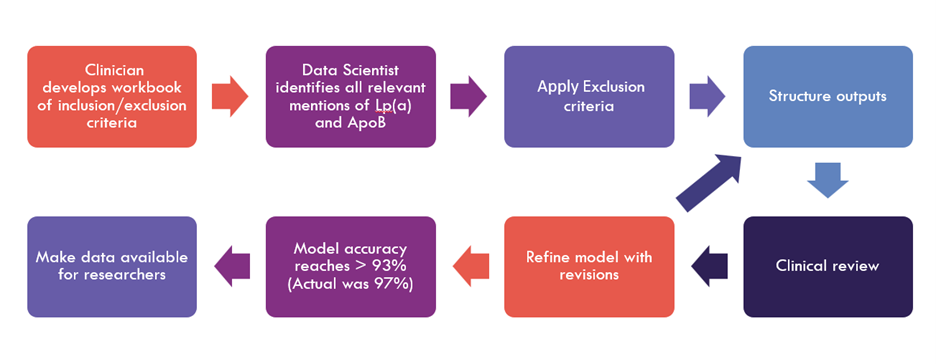
The clinician-developed workbook outlined the inclusion and exclusion criteria for identifying relevant clinical notes. These were shared with the data scientist to guide the extraction process. Inclusion criteria encompassed synonyms, acronyms, common misspellings, codes, and both quantitative and qualitative values within clinically valid ranges. Exclusion criteria included directional language, hypothetical scenarios, references to other lipoproteins being attached to the element, subfractions or subclasses, size-related terminology, and notes lacking specificity regarding the lipoprotein type. (Note: this is not an exhaustive list.)
A rules-based algorithm was implemented to process the notes. Dates, qualitative and quantitative values, and units were extracted and filtered using the previously defined criteria. The structured outputs were reviewed in an iterative process by a clinician, using a sample of 1,000 rows. This review-and-refinement loop continued until accuracy exceeded 93%, with the final model achieving 97% accuracy. The resulting data were then made available to researchers.
Topic modeling via NLP
After extracting relevant notes for ApoB and Lp(a), we applied natural language processing EHR methodologies to identify recurring themes related to cardiovascular risk assessment. The GPT-o3-mini model was provided with few-shot learning examples based on research about why clinicians order these tests. While the model was seeded with examples, it was encouraged to generate new topics beyond them, producing outputs in a structured format: Topic: Description.
This process resulted in 409 distinct unstructured topics for Lp(a) and 264 for ApoB. To merge similar themes—such as “Patient-Driven Inquiry” and “Patient-Initiated Concern”—topic modeling was performed using the BERTopic framework.
BERTopic initially grouped the 655 topics into 12 meaningful categories for each lab. Following a review by domain researchers, overlapping themes were further merged through topic reduction, resulting in 9 final categories for Lp(a) and 5 for ApoB. The most prominent categories are illustrated in Figure 3. Recurring themes included cardiovascular risk assessment and the significance of prior elevated test results as key drivers of ordering behavior.
Figure 3. Top categories from topic modeling, ApoB and Lp(a)
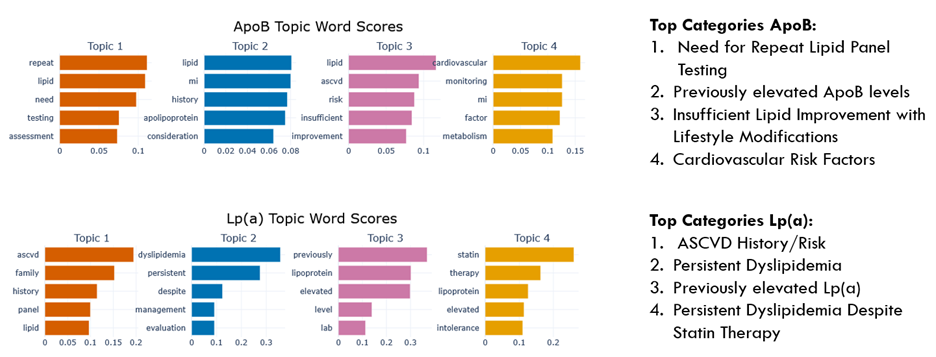
In addition to topic modeling, specific note summaries were extracted to better understand reasoning for testing at the point of care. Specifically, notes unrelated to the top categories identified via topic modeling were selected to show the wide range of conversations at the point of care. Excerpts of note summaries are provided below.
For lp(a), it was noted that “patient is understandably concerned about long term cardiac risk and prefers an aggressive preventive strategy rather than waiting until issues develop.” Another excerpt noted that “Although there isn’t a clear reference to a family history of early cardiac events, issues with statin therapy, or previously elevated Lp(a) levels in her history. This test would help refine her cardiovascular risk assessment and align with her expressed desire to proactively mitigate risks for conditions such as cardiovascular disease as part of her overall anti-aging and wellness strategy.”
For apoB, it was noted that “traditional lipid panels might be underestimating [patient’s] atherosclerotic risk” and “the persistently high number of LDL particles (suggesting discordance between LDL‐C and LDL particle measures) warranted further testing.”
Key insights & future implications
Despite evidence demonstrating the importance of apoB and lp(a) as part of an early and aggressive prevention approach, screening rates remain low (with positive trends). With few exceptions, clinician notes indicate that most patients are screened due to existing comorbidities and elevated “standard” lipid profiles.
Our combined findings from structured and unstructured data suggest that a substantial proportion of the adult population at risk for developing cardiovascular disease is missed via the current standard of care. Natural language processing EHR techniques help uncover critical clinical insights that would otherwise remain hidden in unstructured provider notes, offering an opportunity for more comprehensive risk assessment and improved patient outcomes.
As NLP and LLMs advance, they will drive innovation in disease prediction, personalized treatment, and clinical decision support. These insights help optimize preventive strategies and refine cardiovascular risk assessment to ensure timely interventions for at-risk patients.
Learn about Veradigm’s NLP-powered EHR data solutions and how they support evidence generation in healthcare research. Contact us today to explore how our data-driven insights can enhance your clinical and research initiatives.